Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Статистические обобщения
|
|
Особым видом умозаключений неполной индукции являются статистические обобщения, связанные с анализом массовых событий. К ним относятся, например, массовые транспортные перевозки пассажиров и грузов, рождаемость и смертность людей, распространение заболеваний, транспортные происшествия, динамика преступлений и многие другие.
Учитывая трудности выявления причинных зависимостей, анализ таких массовых событий позволяет установить устойчивое распределение интересующих исследователя случайных признаков. Количественная информация, выражающая устойчивые тенденции развития, имеет важное практическое значение для правильной организации обслуживания населения, профилактических мероприятий, борьбы с преступностью и т.п. Анализ массовых событий ведется чаще всего путем не сплошного, а выборочного исследования отдельных групп или образцов и логического переноса полученных результатов на все их множество. Вывод в этом случае протекает в форме статистического обобщения.
Статистическое обобщение — это умозаключение неполной индукции, в котором установленная в посылках количественная информация о частоте определенного признака в исследуемой группе (образце) переносится в заключении на все множество явлений этого рода.
В отличие от индукции через перечисление при отсутствии противоречащего случая в посылках статистического умозаключения фиксируется следующая информация (1) общее число составляющих исследуемую группу, или образец, случаев; (2) число случаев, в которых присутствует интересующий исследователя признак; (3) частота появления интересующего признака.
Для построения схемы статистического обобщения введем следующие условные обозначения: S — исследуемый образец; р — интересующий исследователя признак; m — общее число наблюдаемых случаев (элементов образца); n — число случаев, когда явление обладает признаком р, f(p) — частота признака р; К — популяция, или множество явлений, на которые распространяется частота признака.
Частота появления признака р в образце S представляет собой отношение числа случаев обладания признаком n к общему числу исследованных явлений m:
f(p) = n/m
Так, например, статистическая информация о совершении такого рода преступлений, как хулиганство, показывает, что 95 из 100 случаев хулиганских действий совершаются в состоянии алкогольного опьянения. Значит, частота хулиганства, сопровождаемая алкогольным опьянением, определяется как 95/100, т. е. равна 95%.
В общем виде частота появления признака в статистических описаниях принимает числовое значение в интервале между 0 и 1: 0 < f(p) < 1. Это объясняется тем, что в статистическом образце S число случаев появления признака (n) всегда меньше общего числа наблюдаемых элементов (m). Поскольку m> n, тем самым f(p) всегда будет меньше единицы, но больше нуля.
В том случае, когда f(p) = 0, это значит, что среди наблюдаемых не обнаружено ни одного явления, обладающего этим признаком. На этой основе может быть построено обычное индуктивное обобщение с отрицательным заключением:
поскольку ни одно S не обладает свойством р, значит, можно заключить, что весь класс К не обладает этим свойством. Точно так же и в случае f(p) = 1 можно построить обычную индуктивную генерализацию с утвердительным заключением. Поскольку число случаев появления признака (n) равно числу всех исследованных (m), т.е. n = m, значит, каждое S обладает р. Отсюда заключают, что весь класс К обладает этим признаком.
Схема статистического обобщения имеет следующий вид:
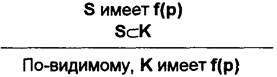
Это означает: признак р появляется в образце S с частотой f; образец S является подмножеством популяции К, которая по числу элементов больше S; отсюда следует, что признак р будет встречаться в популяции К с частотой f.
Статистическое обобщение, будучи выводом неполной индукции, относится к недемонстративным умозаключениям. Логический переход от посылок к заключению дает здесь лишь проблематичное знание. Степень обоснованности статистического обобщения зависит от специфики исследованного образца: его величины по отношению к популяции и представительности (репрезентативности). Если образец по объему приближается к популяции, тем основательнее обобщение, поскольку возможность ошибки становится минимальной. Репрезентативность образца означает меру его представительности: насколько разнообразие элементов в образце отражает их разнообразие в популяции.
Тщательность статистического описания исследуемого образца и логически корректный перенос частоты признака на популяцию обеспечивают высокую вероятность и тем самым практическую эффективность статистических обобщений в различных областях науки, культуры, производства, правовой деятельности.
Контрольные вопросы
1. Как определить индукцию?
2. Чем неполная индукция отличается от полной?
3. Каковы условия повышения степени вероятности заключений в перечислительной индукции?
4. Каковы свойства причинной связи?
5. В чем специфика рассуждений по методу сходства?
6. Как элиминируются обстоятельства при пользовании методом различия?
7. Какова схема и принципы рассуждения по методу сопутствующих изменений?
8. Какова структура статистических обобщений и чем они отличаются от перечислительной индукции?